In 2016, Coursera, one of the leading providers of massive open online courses (MOOC), decided to remove several less popular courses from their site because they weren’t profitable enough to maintain. One of my core beliefs is education should be open and free; anyone that has the passion to learn should be able to regardless of their income, background or location. Unfortunately, when education meets capitalism, those with capital decide what courses live and die while those with a passion for learning miss out.
When Coursera announced they were taking these courses offline I started looking around for a MOOC platform that would host them instead. While many of these courses found their way onto academictorrents.com, and other less legitimate places, these are zips of individual PDF’s and videos, not all-encompassing experiences like Coursera’s classes.
Instead of a centralized service that can increase prices or delete courses at any time, what if we built a decentralized app that anyone can use to explore license-free MOOC’s? They’d never have to worry about a course being taken down or censored, because it can be streamed from anyone else on the network.
Let’s explore the design of a hypothetical application – StudyTime – to illustrate this idea. This is a design document for an application that doesn’t yet exist, but is possible to build.
StudyTime Design Document
StudyTime is an application for viewing and interacting with MOOC’s that runs on Secure Scuttlebutt (SSB). It works by streaming all metadata for courses from the SSB network via SSB Feeds. All non-text content is loaded via SSB blobs, though it can also be made available on other distributed systems such as Sia or Torrents. Because all data is stored locally and mirrored to other clients, the network is self-sustaining as long as it has users.
The application creates its own private SSB key and feed upon first load. Anything that needs to be persisted, such as enrolled courses, course progress, personal notes, friends, etc., is stored in this feed. More interaction between students, such as forums or comparing results between a class, could be added over time using the same back-end and user feeds. Implementing these features would require a lot of thought around moderation and handling spam or trolls and, as such, is out of scope for this design.
User Interface
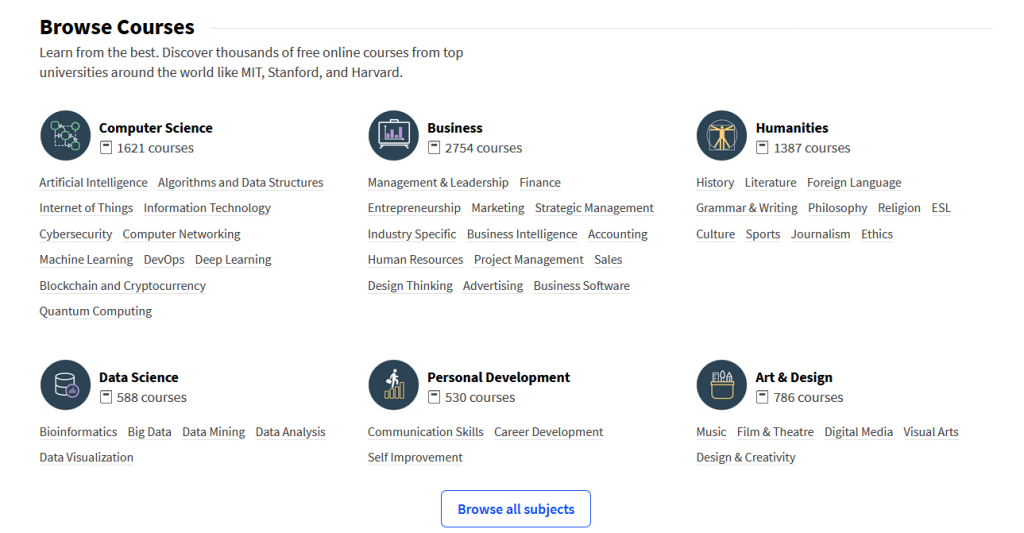
Upon opening StudyTime you are presented with a list of possible subjects to choose from, grouped into major categories with the most popular subjects given higher priority. This could look similar to the homepage for Class Central:
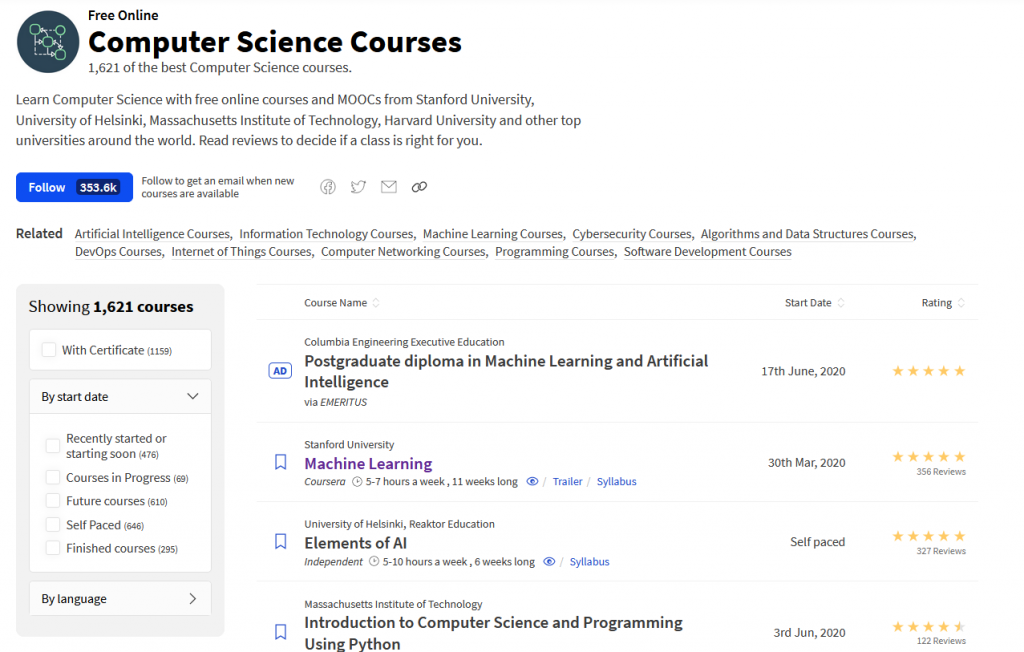
After selecting a category you’re taken to a search page where you can explore all courses tagged with this category. All searching and filtering is done client side.
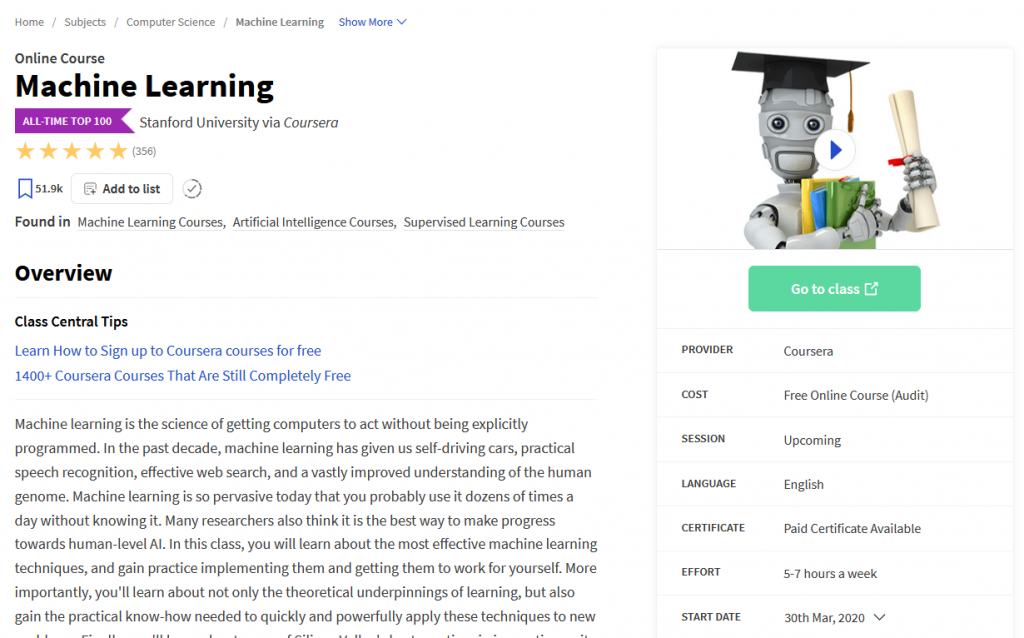
When selecting a course, you’re taken to a course overview page that consists of the course description, estimated duration, a button to start that course, etc..
Most of this front-end design can be based off existing MOOC sites. It’s the back-end of this application that is really interesting.
Back-end Implementation
First, there is one or more course list feeds. Each course in the feed has the type studytime_course. Each course item includes a name, description, keywords, and feed ID. One course list feed ID is hard-coded into the application and is downloaded or updated upon opening the application. Because the course list feed is the primary data source and only one person can add items to the feed, having a hard coded feed creates centralization. The application should not be centralized in any way, so to fix this users will be able to change the course list feed to one created by someone else. Users can load multiple course list feeds (perhaps MOOC providers could release their own StudyTime feeds), and the application will load the courses listed in each. If a course exists in multiple feeds it will be de-duplicated by feed_id and the metadata for the first version found will be displayed in the app.
Here’s what an item in a course list feed looks like:
{
author: '@masterfeed.ed25519',
content: {
type: 'studytime_course',
name: 'Python Essentials',
image: '%c7ZAvQRoEP/zXnXgTnkGafP1JSEV29V8G/+Hhk8lSWU=.sha256',
description: '',
keywords: ['python', 'beginners programming', 'computer science'],
feed_id: 'Pyth0NEsential5.ed25519' // Scuttlebutt feed containing the course's lessons, videos, etc
}
}While the user is browsing, StudyTime downloads the course feeds in the background, so there is little delay when opening a course. The courses will be grouped into categories client-side. Users can search, sort, and filter client-side using the name, description and keywords.
Each course has its own feed, where the author_id is the feed_id in the master feed. Each course feed contains the course content; the lessons and tests it contains, as well as hashes of all the images and videos in the course. When you view an image or video, StudyTime will request it from the SSB network then stream it from other peers who have a local copy. After an image or video is downloaded, the client will automatically share it with other peers to keep the network highly available. Here’s what a course feed looks like:
[{
author: '@Pyth0NEsential5.ed25519',
content: {
type: 'studytime_course_lesson',
lesson_number: 1,
name: 'Week 1 - How to install python',
description: 'This lesson will teach you how to setup Python on your PC',
lesson_content: 'In this lesson we will learn about installing python...'
}
},
{
author: '@Pyth0NEsential5.ed25519',
content: {
type: 'studytime_course_lesson_video,
lesson_number: 1
name: 'Week 1 Video 1',
description: 'How to install Python',
sources: [
'%c7ZAvQXoRP/zXnXgTnkGatP1JSAV29V8G/+Hhk8lSWU=.sha256',
'https://siasky.net/AABAC_3Dt0FJsxqsu_J4TodEETCGvtFf1Uys_3EgzO0Tcg',
'magnet:?xt=urn:btih:a3dced3979cc1a30cc7f648673ced688ce78ce77&dn=studytime-python-essentials'
]
}
},
{
author: '@Pyth0NEsential5.ed25519',
content: {
type: 'studytime_course_lesson',
lesson_number: 2,
name: 'Week 2 - Hello World',
description: 'This lesson will teach you the basics of python programming',
lesson_content: 'First lets run ipython with the following command:\n`ipython`...'
}
}]The front-end uses these feeds to render the course contents and lesson pages, downloading required non-text content as users progress. It pre-fetches all course content in the background after starting a course, so users don’t have to pause at the beginning of each lesson. While browsing through courses, users can navigate quickly as the application is only rendering local data from the feeds.
Updating and Improving Courses
Over time courses may become out-of-date and need to be improved, edited or deprecated. SSB feeds are immutable append-only feeds, so the only way to make changes is via adding messages. A message type studytime_course_update is used to make these updates. Here’s an example of how the Python Essentials course above can be updated:
{
author: '@masterfeed.ed25519',
content: {
type: 'studytime_course_update',
feed_id: 'Pyth0NEsential5.ed25519'
name: 'Python 2.7 Essentials',
keywords: [],
deprecated: true,
}
}This update renames the course to Python 2.7 Essentials, and sets a deprecated flag. StudyTime hides all deprecated courses by default, but could have a “Show Deprecated” option for users that want to see them.
Similarly, course lessons can be updated with a studytime_course_lesson_update message, which contains a new name, description or lesson_content. The lessons will use the latest content when rendering.
Why build this on Scuttlebutt?
Scuttlebutt has a few advantages over building a traditional application with servers:
- The creator doesn’t need to raise money or take down “unprofitable” content to keep the application running, because the community runs it with their collective computing and networking power.
- Provided there are enough users, the application should never go offline, as users are constantly sharing feed data with each other. Because the content is being mirrored so many times, you will always be able to find a feed. Exceptions include images and video, which are harder to keep constantly mirrored, as they are only downloaded by the people that take a course. As a remedy, these images and videos could be mirrored to a service such as Sia or even S3 as a fallback.
- Content cannot be censored or deleted by authorities.
These rules apply to any decentralized application built on Scuttlebutt. I am particularly excited about the first, because there are so many free websites I’ve loved that have closed down over the years simply due to lack of money. If the community supported them with bandwidth and computing power instead, they would last as long as they still have fans.
What are the drawbacks of using Scuttlebutt?
The downsides to using Scuttlebutt rather than centralized servers are mostly constrained to the initial release of the application:
- If there are very few users online it may take a while to find and stream lesson content.
- The developers of StudyTime may need to mirror most of the content until at least a few people have taken every course and are actively seeding the content.
- SSB feeds cannot be changed, so there is no way to remove content once it’s been added. While it can be marked as deprecated/deleted so the application can hide it client-side, users will always have the information.
I hope someone either takes this idea and runs with it or becomes inspired by the potential this network brings. There are so many similar problems in many industries that could be saved with a decentralized back-end like Scuttlebutt.