What if every bank worked together to improve finance for all, instead of competing to extract maximum revenue from every customer? This is happening, today, with Decentralized Finance (DeFi). Its most underrated innovation – Permissionless Composability – is causing an explosion of growth which will lead it to completely dominate global finance this decade.
Composability allows apps to easily integrate with each other. In traditional finance (TradFi) if firms wish to cooperate, they must hold meetings, negotiate a contract, figure out the API, build the integration, have staff on call to keep the API from breaking or going offline. They must write code to handle errors, latency and unexpected results. Then, after all that work either firm may decide they don’t want to cooperate any more, or maintain their API, and shut off access, wasting all that time and effort.
In DeFi these complications disappear. It’s open source and permissionless, you can look at how any app works and build an integration immediately. If you think you can do a better job you can fork them and build your own version. Uptime and latency is handled by the blockchain so you don’t need to worry about services going offline or not returning data quickly. Code is immutable so no one can change their API unexpectedly.
These innovations seem small in isolation, but when combined you can see how this system is a massive improvement over anything we’ve had before. Instead of fragmented, hostile companies writing the same code over and over, not working with each other, and needing many people to maintain this system, you have immutable, stable, open protocols that cooperate with each other. It’s no wonder DeFi has already replicated much of TradFi in under 2 years, and is far exceeding their rate of improvement.
The Curve Composability Wars
What does this look like in reality? An interesting example is the symbiotic relationship between Curve, Convex, and Votium.
Curve is an exchange focused around stablecoins (US Dollars, Euros etc). If you want to trade a LOT of one stablecoin for another it’s the best place to go because it has the most liquidity. These stablecoins are in pools of 2 – 4 coins, and when you trade you send the coin you don’t want to the pool and it sends you the coin you do want.
Curve has a token CRV. To incentivize people to use Curve, they give bonus CRV to anyone who provides liquidity to certain pools.
If you have CRV and lock it up you become a Curve governor and get to vote on what pools get those bonus CRV tokens.
If you have little CRV it’s hard to influence the protocol, and it’s unlikely you’d want to pay the gas cost of locking your CRV tokens for little influence.
Convex, a new app made by a different group, solves this problem by allowing you to lock your CRV in their smart contract, and get cvxCRV in return, which is a 1:1 equivalent to CRV but not locked, and gives bonus CVX tokens. Convex wants all the CRV tokens so that they can direct liquidity to pools of their choice.
Convex is a decentralized app run by CVX token holders, if you hold the CVX token you’ll be able to vote on where the CRV rewards from Convex go. All the additional CRV Convex earns is also given to CVX token-holders.
New stablecoin tokens such as Frax, Fei and UST are constantly being created, and these tokens want lots of liquidity so they are useful and other DeFi apps integrate with them.
Curve is where most people go to trade stablecoins, so these projects want to have large pools of tokens available for people to trade with.
To incentivize their pools to grow, via people adding liquidity, these stablecoin projects want CRV rewards to be given to pools involving their token.
They could do this in 3 different ways:
Beg Curve governors to allocate them tokens (unlikely to work).
Buy CRV themselves and direct CRV emissions to their own pools (long term effective, but could be costly).
Bribe Curve governors to direct CRV emissions to their pool (cheap and effective!)
These stablecoins now want to find Curve governors and bribe them to receive CRV emissions for their pools so they get more liquidity. How do they do this?
Enter Votium – an app that works with Convex allowing protocols to give bribes. It does the math, revealing the protocol giving the most profitable bribes, and allows CVX holders to vote for them. This makes it extremely profitable to be a CVX holder, as you not only receive CRV and CVX rewards, but bribe rewards as well!
What if you don’t have time to explore the different bribes each week and figure out who you want to support? Enter the Llama Airforce Union an app that works with Votium to automatically calculate what apps are giving the best bribes, allocate your votes to them, harvests the rewards, and auto-compound those rewards week after week.
In this tiny slice of DeFi there are 7+ different apps, made by different companies, working together in a cohesive ecosystem to benefit every participant. All these apps cooperate with each other, are open source, permissionless and immutable, and as an investor you are always in control of your funds. As long as there are no un-forseen bugs, you can invest and be certain none of these protocols will change or break for potentially hundreds of years. Your grandkids could still be receiving commissions and bribes from new protocols launching in 2070.
None of this existed even 2 years ago. Curve is 18 months old, Convex is 12 months old, Votium is 6 months old and Llama Airforce is 3 months old. The pace of innovation is continuing to accelerate and new alternatives that enhance this system are launched every day.
Now that curves tokenomics has been proven successful other companies like Frax and Balancer are adding a similar token their products, using the same smart contracts, so that Convex or similar can easily integrate with them too.
Curve itself is still innovating, and many more innovations will continue to be built on top of it. Some basic ideas:
A Wise like app where you can send money anywhere in any currency and it automatically uses Curve in the background to convert to your chosen currency at the best rate possible.
A Forex trading app that allows traders to get 10 – 100x leverage by borrowing tokens and swapping them on curve for the tokens they want. The liquidity required for borrowing could be provided by users in a curve like model too.
Smaller banks can provide cheap currency swaps and use curve in the background instead of having to keep large floats of every currency.
If anyone wants to build these apps they don’t need to go to curve and ask for permission, they don’t need to worry about being blocked or have the API break or change on them – they simply build.
Exponential Growth
Non-composable systems grow linearly, everyone builds unique solutions to each problem. Composable systems grow exponentially. When companies can build on each other problems only need to be solved once, companies can become building blocks for ever greater companies, and creativity flourishes. When you enter a non-composable space you must start from the beginning, building from scratch with little help from existing players. When you enter a composable space you start from the current state of the art, and can easily innovate from there.
How long do you think it would have taken traditional companies to build something like the Curve / Convex / Votium / Llama Airforce relationship? It may happen inside one company, but it’s unlikely it would ever happen across many companies. Why? The risk of things breaking down – what if TradFi Convex decided it doesn’t like bribes any more? Or Curve decides to get rid of CRV voting. All apps downstream of them would be screwed. In DeFi – code is immutable, once a smart contract is deployed it stays there forever, for everyone to build on top of.
We’ve never seen anything like this in finance. It’s a new paradigm and it’s super exciting to be a part of it. The rate of innovation is only going to accelerate, there are many apps building Curve like tokenomics with voting and bribing, and there are many apps trying to muscle their way into the curve wars, all of which grow the profit and usefulness of the system. This curve war is only a tiny slice of what’s happening in DeFi right now, there is so much going on that even working full time in this space I can’t keep up. It’s become fairly obvious that this is finance 2.0 and it’s only a matter of time until the rest of the world realizes that too.
I recently discovered Decentralized Finance (DeFi) and believe it’s the killer app for cryptocurrencies that will propel them into mainstream use. DeFi is going to disrupt finance as much as the internet disrupted newspapers, and eventually it will change the world.
DeFi is financial services devoid of middlemen handling your trades. Instead of fail-able humans, you use an app that interacts directly with smart contracts on Ethereum, a decentralized worldwide computer that nobody controls.
Decentralized Lending and Borrowing
The simplest DeFi apps are lending and borrowing platforms such as Aave. On these you can deposit Ethereum based tokens (known as ERC-20 Tokens) and earn interest on them. Instead of your token going into a vault managed by humans, it goes into a smart contract, and you are the only user who can withdraw your money back out.
Where does this interest come from? Other users can borrow those tokens, and pay interest on them. They don’t borrow your tokens directly, but instead borrow from a pool of all the tokens everyone has deposited.
The interest rate for saving and borrowing are calculated automatically based on the ratio of deposits to loans for each coin. If you have tokens in high demand you could earn upwards of 10% interest on them! Current interest rates are 3 – 5% for stablecoins (Coins worth $1 USD or with little value fluctuation), which is better than any traditional savings account, and you can deposit and withdraw at any time.
What if the borrower disappears with your money? On these platforms all loans are over-collateralized, for anyone to borrow they must deposit some other tokens of equal or greater value. If their loan ever matches their collateral in value, they are automatically liquidated and their collateral is sold to pay off the loan.
Why would you use this if you have to deposit more than you borrow? Let’s say you believe Ethereum is going to go up in value, but need cash now. Instead of selling your Ethereum, you can deposit it, borrow USDC, and use it for your expenses. If Ethereum rises in value, you can sell some to pay off the loan. If it drops below the loan amount, it will be automatically sold to pay off your loan.
Decentralized Exchanges
Decentralized Exchanges (DEX’s) are applications which allow you to trade any ERC-20 token for any other. The most well known DEX is Uniswap. Uniswap runs 24/7 with no human managers, it’s all code. How does it do this? With a concept known as liquidity pools.
Imagine you go to your bank to trade US Dollars for Euros. Your bank has large supplies of both US Dollars and Euros available so they can swap them almost instantly, but they charge you a fee to do so, sometimes as high as 10%! Wouldn’t it be cool if you didn’t have to pay this? Wouldn’t it be even cooler if you were the one collecting the fees? This is one of my favorite parts of DeFi.
Uniswap isn’t a bank, it doesn’t have every token in storage waiting for you to make a trade with it. Instead other users provide those tokens. Lets say you have some USDC and LINK tokens you’re saving for the long term which are sitting in your wallet doing nothing. You could deposit these into a Uniswap liquidity pool, then when anyone wants to trade their USDC for LINK, or vice versa, you get a cut of the fees! You get to rake in the profits banks have been making for years!
Decentralized Stablecoins
Stablecoins are another fascinating innovation in DeFi. If you’d rather not hold Ethereum, Bitcoin or other volatile cryptocurrencies, you can opt to use a token called DAI. One DAI token is always worth 1 US Dollar, and keeps this value through some very clever algorithms. You can get DAI by either trading for it on a DEX, or creating it out of thin air by depositing ERC-20 tokens as collateral in a MakerDAO vault and minting new DAI. Like Aave if your collateral value drops below your DAI value it is liquidated and used to pay off your DAI loan.
With DAI you can participate in the DeFi ecosystem without worrying about the crypto market crashing and taking your profits with it.
Why is DeFi better than existing finance?
Do you know where your money goes when you deposit it in your bank account? When you buy shares do you know where they come from? Do you know how many rent-seeking companies front-run and take a cut of your trades?
Modern financial systems are extremely opaque, and firms like it this way. Being secretive and having powerful friends is useful in finance. You’re able to bend the rules and make risky bets, then bribe anyone who’s allowed to look behind the curtain. As an added bonus, if you make a mistake and lose it all, the government is there to bail you out.
This is in stark opposition to DeFi. In DeFi everything is transparent, you can see the code of the smart contracts you’re putting money into and all trades happening between everyone. Platforms cannot block your trades because they don’t like you or what you’re doing, and bad traders lose their money instead of being bailed out by their powerful friends with money printers.
DeFi is finance made open, transparent, permission-less, and fair. DeFi doesn’t care about your Nationality, Sex, Skin Color or Power. Everyone is on an equal playing field with equal ability to trade, earn income and make a mark on the world.
Remember what happened with Robinhood and Gamestop in January 2021? When the big players started losing money on bad trades they decided to manipulate the system to their advantage using their power. The firm Robinhood used to purchase shares decided they didn’t like retail investors buying Gamestop, because their purchases were hurting their hedge funds friends, so they turned off the tap and stopped retail being able to buy, manipulating markets to their advantage. This is blatantly illegal but they realized they can probably get away with it with a few bribes, I mean campaign donations. This kind of market manipulation isn’t possible in DeFi.
The risks of Decentralized Finance
DeFi is an unregulated, un-policed market. It’s like the wild west, both exciting and risky. There are scammers, rug pulls, buggy code and plain stupidity out there. You could lose what you put in. If you pay attention and take your time to understand what you’re doing you’ll be able to avoid most of it.
The biggest risk right now is what’s known as a rug pull. It’s where a developer will create a DeFi product, such as a decentralized exchange, yield farming opportunity, or loan system. But buried deep in their code is a backdoor, a way for the developer to steal everyone’s funds and ride off into the sunset. This has happened dozens of times and will probably happen again and again. You can avoid these by sticking to only the most well known, audited pieces of software. A great place to start is DefiPulse which lists the top apps by total value locked, most products at the top of this list will be fairly safe against rug pulls, especially if they’ve been audited.
Never put your money into a product less than a month old, no matter how good the returns are is, because some companies will promise the moon in returns only to take your money and run after they’ve accrued a few million dollars.
Should you dive in now and start playing with DeFi with all the risks it contains? Maybe, but I definitely wouldn’t put your life savings in yet, or any money you’ll need in the next few years.
The biggest rewards go to the early adopters, but they’re also exposed to the most risk. The more you learn the more success you’ll have as you’ll be able to tell good deals from bad and earn much higher returns than ever before, without the risk of being a day trader.
Even if you don’t invest anything it’s a super fascinating world to explore, especially if you love technology and finance and have an independent streak (which I imagine is true of most readers of this site). There are some brilliant financial tools being developed in this space, what I’ve described above is barely scratching the surface.
DeFi may not eat the financial system for another decade, but it will eventually. In the same way the internet crushed newspapers and TV, DeFi will crush traditional finance. When consumers have a plethora of choice, it’s unlikely they’ll stick with the legacy financial firms. You can’t stop permission-less, decentralized, open systems, and this is going to revolutionize the world.
Modern day social media is crippling our collective creativity. It has constraints we cannot see but intuitively feel. We’re allowed to post what we like within the confines of the feed and controls of the website, but are we actually free?
Noam Chomsky, a leading intellectual thinking, foretold:
“The smart way to keep people passive and obedient is to strictly limit the spectrum of acceptable opinion, but allow very lively debate within that spectrum….”
Social networks have a lot of problems: from controlling data, to spreading misinformation, to prioritizing profit over users. You’ve heard these arguments before, so they won’t be covered today. Instead let’s discuss a problem gone unnoticed and unsaid: Our creative freedom is being destroyed by lack of control over our experiences on these platforms.
Have you noticed how most social content is from the here and now, an echo of the daily news? Rarely is there discourse on topics that were important weeks ago, let alone months or years ago. Our discourse is limited by these platforms and few realize it.
We’re made to believe we are free to share anything and it will live and die on its own merit. You may think it’s just you, that because you posted something foreign to the weekly news cycle, people didn’t enjoy it. Some people did, some loved your content, but the masses didn’t, and they control the conversation. Stories live and die by their overall popularity, not how significant they are to individual users.
Social media companies amplify the conversations of the day because those conversations keep the average user hooked more than your interesting, unique content did. You’re posting to the perfectly manicured garden they give you. If you attempt to introduce content unfit for the garden it will be buried. It didn’t help the garden have mass appeal, and thus didn’t belong.
This is merely the constraints of an algorithmically determined feed. There’s also hidden constraints in the walls of these products. Why must every Facebook user have the exact same layout with the same event notifications, marketplace link perfectly positioned to draw your attention, the same endlessly scrolling feed. They chose this design because they believe it’s “optimal”, their split tests conclusively proved so. But is an averagely optimal experience really what everyone needs?
What if instead of living in perfectly designed gardens, we could explore a social forest?
Social media is like Keukenhof, a famously beautiful garden in the Netherlands, with flowers in full bloom, trees perfectly trimmed, and not a snail in sight.
What if social media was a forest instead? A place where we could see the mushrooms, bugs feasting on the decaying trees, moss growing along the riverbank. It wouldn’t be as safe and sanitary, but it’s much more fascinating and diverse.
Keukenhof is nice, but do you really want to live there forever? Is it the only place you’d ever want to visit?
What if we didn’t have just one online forest to explore, but many different environments, from forests, to mountains, to swampy marshes, each with their own unique experiences and benefits.
Prior to Social Media the web had diversity, do you remember the GeoCities time? Links could be anywhere, fonts could be anything, websites had endlessly repeating GIF backgrounds. The web was a wonderland of strange and beautiful things to explore. People posted their thoughts on any design they liked and if you wanted to put yourself out there you could do it in any way you desire.
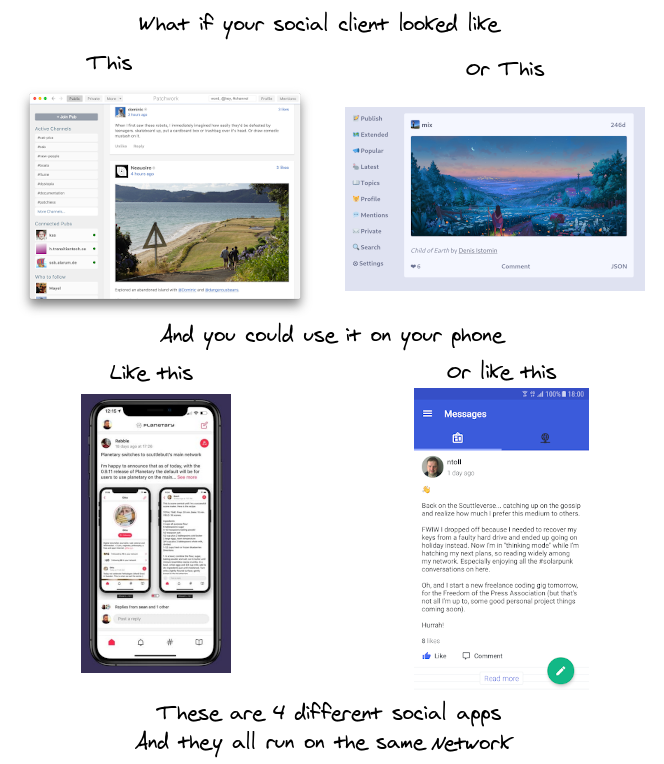
What if we weren’t forced into using the same social client? What if we weren’t forced to use their feed sorting algorithm? What if we could use any one of hundreds of open source feed sorting algorithms, or make our own, and still participate in the same network?
This is the promise of Open Source, Decentralized Social networks. They’re social networks anyone can take part in, and choose how they experience the network. The underlying protocol is the same, but the clients everyone uses are different.
These clients are all real and usable today, and all connect to the same peer to peer network. You and your friends could be using 4 totally different apps but still talk to each other, post images and organize meetups together through them. They’re not as feature rich as Facebook or Instagram but with time they can get there.
There are a number of people writing about this issue, tackling it from different angles. They all point to the same conclusion: If we want a bright social future, we must free it from centralized corporate control.
Why does this make sense now? Because we have the technology to make it possible. When Facebook began in 2005 computers were less than 1/100th as powerful as today’s. It wasn’t possible to build a decentralized social network because someone needed to pay for the servers to hold and distribute the information everyone was sharing. As computing power doubles roughly every two years (and has been doing so for the last 75 years) we now have more than enough space and power to build networks that run on our personal devices.
Through a series of articles first analyzing the problem, why the answer must be open source and decentralized, and finally the solution. I’ll walk you through explaining why this is such an important topic and why it must be done to unlock maximum creativity from humanity.
André Staltz is a passionate believer in a new decentralized social web, and he eloquently lays out what’s wrong with existing social media.
In the beginning, the web was created as the hypertext — a graph where the documents are the nodes and the hyperlinks are the edges. It made a lot of sense for academics, at a time when the desktop had the best user experience. Writing HTML was not that bad for academics already comfortable with markup like LaTeX for papers.
The social web emphasizes posts, which can be short messages or pictures. They don’t need to be authored in markup like HTML.
The user experience is comfortable for everyone. The UX of content creation is important, because it means the social web grows faster than hypertext, and eventually will outgrow the web itself. I believe we may have passed this point already.
Sounds great right? Easier content creation means more content from everyone, we can all participate instead of just a handful of designers.
We could embrace this new era and just forget hypertext. But the problem is that the social web is made out of a handful of closed platforms, whereas the web is open.
On the closed social web, there are many problems. We lack freedom, innovation, trust, respect, and transparency.
Innovation on these platforms is dying. Third party apps are taken down, and there is little diversity in the UI choices. We become passive consumers of UX decisions by the tech giants, and we don’t have any control over newsfeed algorithms.
We’ve gotten used to closed platforms making decisions for us, but there’s a huge opportunity for innovation that’s unlocked in an open protocol.
These platforms provide a simple way to create content, but only if you stay inside their perfectly manicured garden.
André has a solution to this problem,
So, what if we take this idea that works, and reinvent it with a coherent and open protocol?
Scuttlebutt is a peer-to-peer open protocol for social networks. It was created in 2014 by Dominic Tarr and other NodeJS hackers. I joined in 2016.
We’ll touch on Scuttlebutt more soon in this article, if you want to know more about it, check out his post.
Now we get to the core problem of blandness in social networks.
When Yahoo shut down GeoCities, they did much more than delete a bunch of obnoxious dancing baby GIFs and Limp Bizkit MIDI files. They deleted the ability for people (both old and new to the web) to easily create web sites, and be in complete control of the content and presentation they provide to their audience.
Sure, some of the old sites weren’t “great”. But they were fun, and quirky, and interesting. We used to call it “surfing” the web, and that was actually a good way to describe it. There was a certain adventure to the activity – a fun and excitement in exploring the unknown.
Go to a Facebook profile, and ponder what we have now. Instead of having adventures into the great unknowns of the web, we instead now spend most of our time on social networks: boring, suburban gated communities, where everybody’s “profile” looks exactly the same, and presents exactly the same content, in the same arrangement. Rarely do we create things on these networks; Instead, we consume, and report on our consumption. The uniformity and blandness rival something out of a Soviet bloc residential apartments corridor.
The other core problem of social media is most people have their real identities tied to the network, so you can’t talk about anything too taboo or provocative, as he continues:
And when you don’t have to attach your real identity to everything you do, it still doesn’t matter how old you are, what you look like, or what your social class is
Neocities is somewhat solving this creativity problem, and I love that it exists, but it’s not a social media platform.
One of the core problems of social networks is they’re all owned by massive corporations that must return profits to shareholders. Even if alternative networks are created they will need to generate a profit to survive, which causes them to focus on the keukenhof experience, instead of letting the forest grow unwieldy.
These corporations have all the incentives to make their social network closed off to outside competition, lest they lose users to them. As they grow they become more insular to protect what they’ve built.
The solution is not another social network with some additional customization, the solution is a decentralized protocol that hundreds of social networks and social clients can connect to, and use to interact with each other. This gives everyone the freedom to choose the platform they want to be a part of, to choose the UI they love. If any of these platforms turn evil you can easily take your data and leave to a better platform, without having to bring all your friends with you.
Moving to a world where protocols and not proprietary platforms dominate would solve many issues currently facing the internet today. Rather than relying on a few giant platforms to police speech online, there could be widespread competition, in which anyone could design their own interfaces, filters, and additional services, allowing whichever ones work best to succeed, without having to resort to outright censorship for certain voices.
At the same time, it would likely lead to new, more innovative features as well as better end-user control over their own data. Finally, it could help usher in a series of new business models that don’t focus exclusively on monetizing user data.
He continues, the best analogy for how social networks should function is like email. We can all use different email providers and yet still communicate with each other. Why don’t social protocols work in the same way?
However, because of these open standards, there is a great deal of flexibility. A user can use a non-Gmail email address within the Gmail interface. Or he or she can use a Gmail account with an entirely different client, such as Microsoft Outlook or Apple Mail.
On top of that, it’s possible to create new interfaces on top of Gmail itself, such as with a Chrome extension.
This setup has many advantages for the end user. Even if one platform—like Gmail—becomes much more popular in the marketplace, the costs of switching are much lower. If a user does not like how Gmail handles certain features or is concerned about Google’s privacy practices, switching to a different platform is much easier, and the user does not lose access to all of his or her old contacts or the ability to email anyone else (even those contacts that remain Gmail users).
Notice that this flexibility serves as a strong incentive on Google’s part to make sure that Gmail treats its users well; Google is less likely to take actions that might lead to a rapid exodus. This is different than a fully proprietary platform such as Facebook or Twitter, where leaving those platforms means that you no longer are in communication in the same way with the people there and can no longer easily access their content and communications. With a system like Gmail, it is easy to export contacts and even legacy emails and simply begin again with a different service, without losing the ability to remain in contact with anyone.
One key insight is with a diversity of platforms to choose from, and little cost from switching, as all your contacts come with you, platforms are incentivized to do good by their users lest they leave the site.
In addition, it opens up the competitive environment much more. Even as Gmail is an especially popular email service, others are able to build up significant email services—like Outlook.com or Yahoo Mail—or to create successful startup email services that target different markets and niches—like Zohomail or Protonmail.
Imagine a competing interface for Twitter that would be pre-set (and constantly updated) to moderate out content from trollish accounts, and to better promote more thoughtful, thought-provoking stories, rather than traditional clickbait hot takes. Or an interface could provide a better layout for conversations. Or for news reading.
A protocol system, by its very nature, would likely lead to much more innovation in this space, in part by allowing anyone to create an interface for accessing this content. That level of competition would almost certainly lead to various attempts to innovate, improving all aspects of the service. Competing services could offer a better filter, a better interface, better or different features, and much more.
Jack Dorsey at Twitter recently announced BlueSky the formation of a new team to build a decentralized social media protocol. Jack has realized this is the future of social media, and it would be beneficial to Twitter because they no longer need to be bastions of speech, they can kick undesirable users off their platform but not off the network, similar to email.
This is a great step in the right direction of where social media should go to unlock human creativity.
Sriram talks about the existing problem with social media platforms:
Imagine if Gmail was the only email client ever developed and SMTP+IMAP had never existed. Gmail could have defined all things email
But that is not where we find ourselves since SMTP does exist. These are open, documented standards which have evolved over years of open development.
Now, compare this with the current state of any social media product. You get a full “stack” – some of the most complex, intricate systems ever built in tech – which combines everything from relevance algorithms, content policies, verification policies, identity, incentive structures among many other things.
So how can we build a better social network – through BlueSky’s proposal.
Alternate ranking models: every social platform uses a complex feed ranking algorithm optimizing for a combination of factors – community interaction, engagement, likelihood of spending time, etc. However as a customer you don’t get a choice of using different models. Imagine opening up any social platform and switching to a ranking that optimizes to show you only insightful content – or joyful content – or the most recent content. Or one that ranks content from people who typically don’t get attention. Or one that just shows you Keanu Reeves content. You can imagine a marketplace of “ranking models” and you get to plug and play any one.
Being able to change your ranking algorithm would be game changing. Imagine if you could choose to only see content from your best friends, only see the best content in the last year instead of the last 2 days, only see stories that received positive feedback, ignore all political content etc. There are so many different ways to make our feed full of exactly the posts we want to see.
This would lead to much more overall happiness, when we know we’re in control of what we read, instead of some AI algorithm optimized for engagement.
Alternate verification policies
Alternate content moderation policies
Both extremely useful features to a social network, we can have many social network providers do verification, spam checks, block harassment etc, but all of the platforms can talk to one another and you can choose the community that suits you while still being able to connect and interact with those in other communities.
Now for my favorite solution to decentralizing social media, a protocol known as Scuttlebutt. It’s free, open, and everything you’d hope for in a social protocol. There are already a number of clients running on Scuttlebutt which can talk to each other, but first let’s see what the man behind the machine has to say:
For Tarr, the philosophical underpinning of Secure Scuttlebutt is social relativism. Because Scuttlebutt is distributed, each user decides what to do with their network and how to do it. This means that the users of SSB-driven software must consciously deliberate about whom they want to interact with “online,” and where, and why.
Commercial online services, by contrast, regulate user behavior with software and legal controls. Even the way users are identified on a service like Twitter, Instagram, or WhatsApp must conform with the service provider’s wishes. A username is a globally unique ID. Otherwise, how would the service and the users tell one individual from another?
Scuttlebutt doesn’t assume a replacement circumstance; instead it opens the door to many alternatives—the libertarians can have their markets, and the leftists can have their coops, and others can have anything in-between.
By building a network with many clients, many platforms and many possible ways to experience your social world, it doesn’t matter what your desire, you can find the perfect platform and group for you. Or if it doesn’t exist, create your own.
Centralized services are easy to use, but they offer one-size-fits all solutions. Why should a social network for a school or a family or a neighborhood work the same way as one meant for corporate advertisers, or governmental officials, or journalists? Even if Scuttlebutt never catches on, it shows that the future online might be far more customized and diverse than the present. And not just in its appearance, like MySpace or GeoCities. But also in its functionality, its means of access, and its membership.
Another new decentralized social protocol I’m fascinated by but haven’t used much yet is ActivityPub. The biggest known social network using this protocol is Mastodon. Jeremy wrote this excellent piece explaining why it’s so exciting:
There’s a new social network in town. It’s called Mastodon. You might have even heard of it. On the surface, Mastodon feels a lot like Twitter: you post “toots” up to 500 characters; you follow other users who say interesting things; you can favorite a toot or re-post it to your own followers. But Mastodon is different from Twitter in some fundamental ways.
Mastodon isn’t controlled by a single corporation. Anyone can operate a Mastodon server, and users on any server can interact with users on any other Mastodon server.
This decentralized model is called federation. Email is a good analogy here: I can have a Gmail account and you can have an Outlook account, but we can still send mail to each other. In the same way, I can have an account on mastodon.technology, and you can have an account on mastodon.social, but we can still follow each other, like and re-post each other’s toots, and @mention each other. Just like Gmail servers know how to talk to Outlook servers, Mastodon servers know how to talk to other Mastodon servers (if you hear people talking about a Mastodon “instance”, they mean server).
This federation is done via a new protocol called ActivityPub, which is an open source standard that different social networks and servers within a social network can use to talk to each other.
ActivityPub is a social networking protocol. Think of it as a language that describes social networks: the nouns are users and posts, and the verbs are like, follow, share, create… ActivityPub gives applications a shared vocabulary that they can use to communicate with each other. If a server implements ActivityPub, it can publish posts that any other server that implements ActivityPub knows how to share, like and reply to. It can also share, like, or reply to posts from other servers that speak ActivityPub on behalf of its users.
ActivityPub is much bigger than just Mastodon, though. It’s a language that any application can implement. For example, there’s a YouTube clone called PeerTube that also implements ActivityPub. Because it speaks the same language as Mastodon, a Mastodon user can follow a PeerTube user. If the PeerTube user posts a new video, it will show up in the Mastodon user’s feed. The Mastodon user can comment on the PeerTube video directly from Mastodon. Think about that for a second. Any app that implements ActivityPub becomes part of a massive social network, one that conserves user choice and tears down walled gardens.
This protocol could be amazing! Tying together various sharing sites, social networks and content platforms into one cohesive social web.
“Network effects” leaves kind of a dirty taste in my mouth. It’s usually used as a euphemism for “vendor lock-in”; the reason that Facebook became such a giant was that everyone needed to be on Facebook to participate in Facebook’s network. However, ActivityPub flips this equation on its head. As more platforms become ActivityPub compliant, it becomes more valuable for platforms implement ActivityPub: more apps means more users on the federated network, more posts to read and share, and more choice for users. This network effect discourages vendor lock-in. In the end, the users win.
This is a powerful argument for why ActivityPub could eventually be the social standard online that even the current centralized platforms have to implement to keep up. I’m super excited to see how it develops and see new platforms adopt the protocol, making it continually more useful over time.
Fixing the closed social web
Now that you understand the benefits of an open web, you’ll start to realize how dreary and restrictive the existing web is. Over time with enough fans, programmers and funding we can make this new decentralized web just as feature rich and populated as the existing social web. Then we’ll have a much brighter, more free social future for all of humanity now and into the future.
Public social networks, comment sections, and discussion forums are broken. The internet promised limitless access to knowledge and thoughtful, intelligent conversations with people from all over the world. Instead, we have trolls, manipulators, outrage, and spam.
It might seem like decentralization would make these problems worse. After all, most decentralized or unmoderated social networks turn into dumpster fires of low quality content over time. Without moderators or the threat of being banned, the worst users feel emboldened to spread their drivel across the entire network. As quality degrades, the best users are turned off and the network becomes less useful and engaging.
But there is a solution that gives power back to the people, allowing them to moderate their own world, working with friends to keep it free from low thought discourse. It works by mirroring the real world: give everyone a reputation and the ability to ignore those with a poor reputation.
In this article I’m going to show not only how a decentralized moderation system can be as good as existing systems, but also surpass them, creating a higher quality social network.
But first, let’s take a step back and see what centralized moderation gets wrong.
Centralized Moderation and its flaws
Centralized moderation refers to social networks or forums where one central entity, such as a corporation or the owner of the site, has sole moderation authority over the contents. There is usually one set of rules that all users must follow and if skirted the user’s content is deleted and repeat offenders are banned.
The flaws center around content that some users enjoy and others do not and how you deal with that content.
With centralized moderation we all have to play by the same rules, so sites have to do the best job they can. If they are overly harsh in moderating they’ll have a good signal-to-noise ratio, but the content may become overly partisan or boring. If they’re too lenient the content will get noisier which makes it less enjoyable as there are then more low effort posts to sort through. And some of the worst content will turn many people off.
Content Spectra
Imagine rating every piece of social media content along a content spectra of the following:
Low Quality → High Quality
Low Offense →High Offense
Accurate → Inaccurate
Consider where the content you enjoy most fits on these spectra. It’s likely not a fixed point, but rather a range of what is considered acceptable and a smaller range of what is considered ideal.
The worst content generally lies at the extreme of these spectra. Spam is extremely low quality, Haters are High Offense, and Manipulators are Frequently Inaccurate.
So, a site has a good signal-to-noise ratio when a good percent of the content falls into one’s ideal zone.
Users want to see content that falls into their ideal zone, rather than have to hear everyone’s opinion. If too much falls outside their ideal zone they’ll often become bored and leave the site.
Sometimes heavy moderation of content that falls outside of one’s “ideal zone” is a good thing, because it means you’ll enjoy the content you read more, without having to wade through purely acceptable content.
The central flaw of centralized networks is that by having a set of rules that all users must abide by, sites are presetting the allowable content spectra. This content spectra not only decides the kind of users that will be allowed on the site, but also those attracted to the site, because the users whose content spectra more closely match the website will tend to stick around more.
It turns out centralized services have thought about this problem over the past decade and have come up with a solution: algorithmically determined feeds. If everyone has their own feed, an AI algorithm can learn what one’s ideal content spectra is and show the content that most appeals to them. This feed is a filter on the world that helps one view the site in a curated “ideal” light.
Algorithmically determined feeds are the next stage in the evolution of social networks, but these feeds have their own set of problems.
The Algorithmically Chosen Feed Problem
Having a social feed driven by an algorithm can be useful for surfacing all the content you’d like to see most on a social network, but it also has dark sides that most rarely think about.
The biggest problem with utilizing algorithms to customize social feeds is that the user has no insight into the decisions the algorithm makes. With the rise of neural networks, at times even the developers of these algorithms are unable to explain their internal logic.
When a post is made, even one into which a lot of time and effort has been put, the algorithm may decide that it’s low quality, rank it lowly, and cause it to never appear in friends’ algorithmically chosen feeds. Under this paradigm, neither a user nor their friends’ opinions matter, the algorithm has decided and its decision is final.
Furthermore, because these algorithms are applied to millions or even billions of people, there is a large financial incentive for manipulative companies or organizations to reverse engineer them. If they can figure out how these algorithms work, companies can tailor the algorithms to prioritize their own content to reach the top of as many feeds as possible. This becomes worse if the social network’s financial incentives are aligned with the company’s. Even if the social media network itself is completely benevolent, this will always be an issue.
One final flaw of these algorithms is the incentive for social networks to keep you hooked on their product. This means that the algorithms are optimized to display content you like and hide the content you don’t like. Though useful in moderation, this can quickly turn dangerous if optimized for dopamine hits and short term emotional appeal over mental health and well-being.
Who chose the moderators?
Centralized moderation has a fundamental, rarely discussed, issue: The idea that a third party is needed to moderate user’s content.
Why can’t we decide that for ourselves? Why do we have to be subject to the whims of covert moderators and opaque algorithms that decide who is allowed and what content is acceptable?
Decentralized worlds do not have to be structured in this way. Decentralized networks have the potential to fulfill the original intent of the internet: worlds open to everyone without global rulers in which everyone is able to participate and moderate their own domain. Users choose who to trust, who to ignore, and how one’s feed is ordered.
The Solution: A Decentralized Moderation System that scales to everyone
To have the best social experience possible, moderation must be personalized. Individuals must be able to decide who can be a part of their world and who cannot. It’s not possible for any company to make policies that millions approve of and that do not have downsides and unintended consequences.
This doesn’t mean that global moderators are no longer necessary. They are still incredibly useful, just no longer mandatory. Instead, moderators should be opt-in, leaving an individual, or group of individuals, to choose the moderator for one’s “world.”. This allows users to benefit from companies that specialize in detecting and eliminating spam, bot networks, or Astroturfing, without being forced to use them.
How it works
In real life trust comes from friends and family, the people someone already trusts to help determine who can and cannot be trusted. When a friend begins to associate with bad people one either tries to steer them away or one’s trust in them falls.
This is exactly how the new decentralized trust system works. A user rates the trustworthiness of some of the people encountered online, and then trust of everyone else is calculated based on these ratings. In this implementation the trust ratings must be public, so that everyone can calculate the trust of friends of friends. In the future a more private trust system could be developed along similar lines.
The second part is a filter that a user can apply to their social feed to hide everyone with a trust rating below a particular threshold.
Now this isn’t a finalized spec, it’s a rough outline of how this system can work. This essay is about why we should build this and how it could work, more than exact implementation details.
To bootstrap the system the user would first give a rating to the people they trust/distrust on the network. These might be people known in real life or not. Ratings can be between -100 and 100. This rating should be how much a user trusts them to post content that is similar to their ideal content spectra, because these ratings will shape the content seen on the social network.
When a user encounters new people online they can give them +/- 1 votes based on individual pieces of content posted. For obvious spammers or trolls one could immediately give them a negative rating.
So, while individual pieces of content can be rated the trust rating is given to a person. This is because most people post content in a similar content spectra. However, it is important that trust is also linked to content so that when a user asks the question “Hey, why does my friend distrust this guy?”, they could see the exact piece of content that caused the distrust.
After a few trust ratings have been given, the algorithm will go on to calculate the trustworthiness of friends of friends (two degrees of separation away) and even their friends (three degrees away). It does this by taking all the people a user trusts and all the people they trust, then multiplying the trust levels together to come up with one’s own personal trust rating of everyone else. Even if a user only rates ten people, then those ten go on to rate ten others and those rate ten others, this will result in the user having trust ratings for over 1000 people on the network.
When a trust rating is given it is fixed and not affected by the ratings of others.
The people a user distrusts have no effect on their trust rating of others. This is just like in real life, where when someone encounters someone they don’t like, they don’t care who their friends or enemies are. It also prevents malicious users from gaming the system.
Now instead of having to individually block spammers, trolls and haters from your world, as soon as a trusted friend rates someone poorly, they’ll be hidden automatically, making moderation of obvious trolls or spammers much easier.
The Algorithm
The general algorithm is: the trust rating of anyone who does not already have a set rating is the square root of how much a user trusts a mutual friend multiplied by how much the mutual friend trusts the stranger. In the case of negatives the negative is ignored when calculating the square root (so there’s no imaginary numbers). When a user has multiple mutual friends their scores are summed before the square root and that number is divided by total raters (so that someone who’s popular isn’t naturally more trusted).
There is a small flaw with this algorithm. If a user has a friend Alice that is rated at a ten, and then they have a best friend Bob that is rated at 100, the score for bob will be (10)(100)= 31.6.
This is weird because the user doesn’t trust Alice that much, so why would they trust Bob more than her? We can make an improvement to address this: the trust level is capped to how highly the mutual friend has been rated.Similarly to real life, if an acquaintance brings a friend to a party, it doesn’t matter how much they say they like them, they still will not be trusted higher than that acquaintance.
Here’s a demo to showcase this system in action, with randomly generated users that randomly trust other users are random levels:
Total Users
AVG Ratings Per User
Trust Depth
You can adjust the total users and average ratings per user to see how the system works as more people join in and use it. You can also adjust the depth, or degrees of separation, that the trust ratings are calculated for.
The arrows represent how much each user trusts the user the arrow is pointing to. The color of each user represents how much they are trusted by the selected user (the blue one), calculated via the algorithm described in this post. Bright green represents 100 trust and bright red -100 trust, with a gradient for scores in between.
The source code for this demo is open source on Github. I’ve implemented a simple version of the trust algorithm in JavaScript which you can use for your own social network if you wish and it’s already fast enough for most use cases.
Technical Implementation
This can be implemented on top of Scuttlebutt, or any other open source social network. With Scuttlebutt the only requirement is a trust plugin which allows users to post trust-rating messages that contain a user/feed ID and their rating of that user. With that information, the algorithm can calculate the trust rating of all users based on the trust-rating messages everyone has posted.
In regards to user experience, this plugin could add upvote/downvote buttons to each piece of content that increases or decreases trust in the user that posted that content. The trust filter can be a simple drop-down in the top right of the feed that, when a trust level is chosen, all posts by users with a trust rating below that level will be hidden.
In terms of performance, the demo above utilizes a simple algorithm in JavaScript, and even this is able to re-calculate the trust of 100,000+ people in just a few milliseconds. You can see the benchmarks here.
This can scale to hundreds of millions of users because each user only needs to calculate the ratings of a few hundred to tens of thousands of people. Because it’s open source this algorithm can be updated and improved over time if better ways of calculating trust are discovered. A written text example of this algorithm is in Appendix A.
Additional Benefits of Decentralized Trust
Choose your own moderators
It’s still a good idea to have large organizations become moderators, because they have more resources and clout than individuals. The difference is, in a decentralized world, one can choose their own moderators. Imagine a future where the New York Times has their own “Trust Beacon” user on the platform. Whenever they report on fake news or fake content , this trust beacon can mark the content and those who post/create it at say -10 trust.
If a user trusts the New York Times, they can rate it at say 50 trust, and it will apply it’s trust ratings to their social feed automatically. It’s the same as trusting any other user.
These trust beacons could be set up by any media companies, fake news catching websites, or even companies like NetNanny that want to filter out content unsafe for kids. People can trust anyone they like and then those trust ratings will be applied to their feed. This way a big network of friends is not needed to help filter content, these companies can do so if desired.
Trust can be linked to posts or images
This trust system doesn’t need to only apply to users. It can be applied to individual posts or pieces of content. For example, on Scuttlebutt every piece of media is stored as a blob, where the filename is a hash of it’s contents. This hash is essentially a fingerprint of image, video, song, etc. on the network.
A trust beacon such as Snopes that debunks false information can have an account that flags images that are false. Because that image can be identified across the network by its hash, if a user subscribes to the Snopes trust beacon it can automatically flag and filter this content for them even if that image was reposted 100 times before they saw it.
This could also be done with pornographic or violent content that’s unsafe for kids. Services such as NetNanny could maintain a list of these adult only images and videos and automatically block them for children, creating a safer space for them to explore than even the major networks can manage.
You choose what trust means to you
The interesting thing about this system is that a user doesn’t have to trust people based on truthfulness. Trust is an arbitrary number that can be used to represent anything one would like to see more of in your social world. If a user wants trust ratings to be based on shared beliefs, positivity, or even geographical proximity that’s up to them.
Imagine a world where instead of everyone having one social profile, they have one profile for every topic they’re interested in. One could have a profile for programming, for politics, for games, for decentralization, etc. If this becomes commonplace then one’s trust in someone can be directly related to their area of expertise. Trust is often not in the person but in one’s confidence that they know about whatever they’re talking about at the time.
Alternatively, it could be implemented in such a way that people have multiple trust ratings, each tagged by topic. However that would add a lot more complexity, especially around identifying what topic each post belongs to.
Creating Small Communities again
Most of the time friends are chosen through serendipity. It’s been shown that the secret to a friendship blooming is multiple random encounters. One reason people rarely make friends via major social networks (Twitter, Facebook, Reddit, etc.) is because they are so large and spread out people rarely encounter the same person twice if they’re not already friends.
Imagine if your social feed showed everyone you follow, as well as everyone they follow, with their rank based on trust ratings. You may discover some good friends of friends that you’ve never met posting content that you really like. Over time you could comment on their posts, contribute to the conversation, and, eventually, form a relationship.
The trust system would allow the best friends of friends to appear in user’s feed more often than a random crazy uncle, posts from groups, or even barely known acquaintances. This could lead to new connections and many amazing new friendships with people that were previously just out of contact. The more interests and people in common, the more users will see each other online and the more chances they’ll have to connect.
This is internet scale moderation
The future will be full of AIs and bots that create hundreds of thousands of accounts in order to take over social networks. With decentralized trust all it takes is one friend or trust beacon to notice these bots and distrust them. It needs to be possible to scale moderation to the level where it can combat thousands or even millions of fake users and bots. It can’t scale by having designated moderators, it can only scale if everyone participates in moderating some portion of the world.
Downsides of Decentralized Trust
Now there are potential downsides to this system. As with anything, when people are given freedom some people are going to use it poorly. That’s okay. People shouldn’t be told what to do anyway.
The first obvious issue is the creation of echo chambers or online cults, where instead of choosing truth and seeking the best information, people trust those who confirm their existing beliefs.
This can be somewhat mitigated with the ability to set a trust filter level to a low level, even in the negatives, to see posts and opinions one may not usually be exposed to. This again is up to the end user if they wish to expose themselves to differing opinions or not.
It is up to individuals to determine what’s best for them. Of course, one would hope they make good choices, but it is not society’s job to save people from themselves. It’s far better to have this freedom and the power to use or misuse it, than to allow companies to build the echo chamber behind closed doors.
Conclusion
The implementation will be open source and open to anyone to participate. Implementation has already begun, however there is a lot of work to do. If anyone has heard of anyone building something similar it would be wonderful to meet so this idea can be brought to fruition.
It’s exciting thinking about the possibilities this system would bring. There is potential for more stimulating conversation threads without trolls trying to ruin the fun. With the current state of the social internet this is hard, but it’s something worth doing.
Appendix A: Trust system example
Lets walk through an example, starting with Tom.
Tom has a best friend Alice, who he trusts at 100
Tom also has a friend Mike, who he trusts at 50
Alice knows a guy Dave, who’s a compulsive liar and trusts him at -20
Alice has a workmate Jeremy who’s an ok guy but she doesn’t know him well, so she trusts at 10.
Alice has a workmate Sophie, who constantly shares false outrage, but is otherwise a good person, who she trusts at -5.
Mike is best friends with Jeremy and trusts him 40
Mike knows Sophie and likes her, and trusts her 15
Dave has a best friend Barry, who he trusts 100
Sophie has a best friend Emily, who she trusts 100
While Tom has only rated 3 people, the Trust Software will now calculate his personalized trust ratings for all 7 people here:
First there’s the immediate friends, if you’ve rated someone that is the fixed rating for them, it isn’t influenced by anyone else:
Then the secondary friends:
Then the tertiary friends:
Barry is unrated as Tom.Dave < 0
There’s a few interesting things happening here. First, Sophie ends up with a slightly positive trust rating despite Tom’s best friend Alice saying she shares too much false outrage. This is because Mike still trusts her. If Tom notices that she does share a lot of false information he can either rate her himself which will mean his friends ratings no longer apply, or he can rate Mike lower because it’s becoming obvious Mike doesn’t care about truthfulness as much.
We also see that Barry’s rating is not calculated at all (so would default to 0). This is because if we don’t trust someone we also don’t trust anything they have to say about the reputation of others, so the system can’t be gamed by malicious actors. Similarly if Tom rated Sophie at a negative number then her rating of Emily would no longer apply and Emily would have the default rating of 0.
Lastly we see Emily’s rating is capped to the same rating as Tom.Sophie, because we never rate friends of friends higher than the mutual friend.
All the people above are now in a big discussion about politics and Tom can see this discussion happening in his feed. As Tom wants to be well informed without liars being involved he sets his trust filter level to 10, so everyone with less than 10 rating will be hidden. This allows Tom to filter his world without investing much effort in the process. In this feed he would only see posts from Alice, Mike, Jeremy and Emily. Posts from Sophie, Dave or Barry would be hidden.
In 2016, Coursera, one of the leading providers of massive open online courses (MOOC), decided to remove several less popular courses from their site because they weren’t profitable enough to maintain. One of my core beliefs is education should be open and free; anyone that has the passion to learn should be able to regardless of their income, background or location. Unfortunately, when education meets capitalism, those with capital decide what courses live and die while those with a passion for learning miss out.
When Coursera announced they were taking these courses offline I started looking around for a MOOC platform that would host them instead. While many of these courses found their way onto academictorrents.com, and other less legitimate places, these are zips of individual PDF’s and videos, not all-encompassing experiences like Coursera’s classes.
Instead of a centralized service that can increase prices or delete courses at any time, what if we built a decentralized app that anyone can use to explore license-free MOOC’s? They’d never have to worry about a course being taken down or censored, because it can be streamed from anyone else on the network.
Let’s explore the design of a hypothetical application – StudyTime – to illustrate this idea. This is a design document for an application that doesn’t yet exist, but is possible to build.
StudyTime Design Document
StudyTime is an application for viewing and interacting with MOOC’s that runs on Secure Scuttlebutt (SSB). It works by streaming all metadata for courses from the SSB network via SSB Feeds. All non-text content is loaded via SSB blobs, though it can also be made available on other distributed systems such as Sia or Torrents. Because all data is stored locally and mirrored to other clients, the network is self-sustaining as long as it has users.
The application creates its own private SSB key and feed upon first load. Anything that needs to be persisted, such as enrolled courses, course progress, personal notes, friends, etc., is stored in this feed. More interaction between students, such as forums or comparing results between a class, could be added over time using the same back-end and user feeds. Implementing these features would require a lot of thought around moderation and handling spam or trolls and, as such, is out of scope for this design.
User Interface
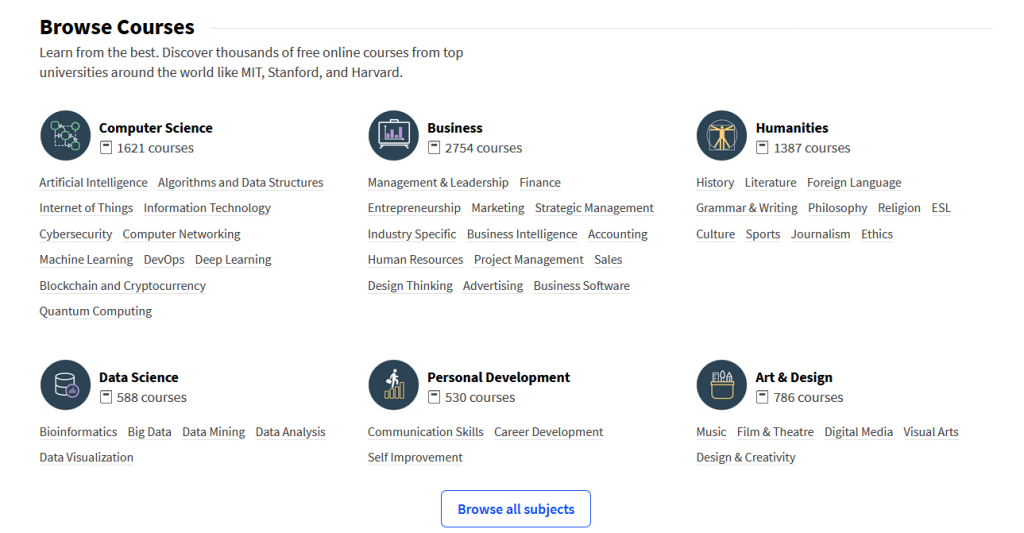
Upon opening StudyTime you are presented with a list of possible subjects to choose from, grouped into major categories with the most popular subjects given higher priority. This could look similar to the homepage for Class Central:
Screenshot from Class Central Homepage – select subject section.
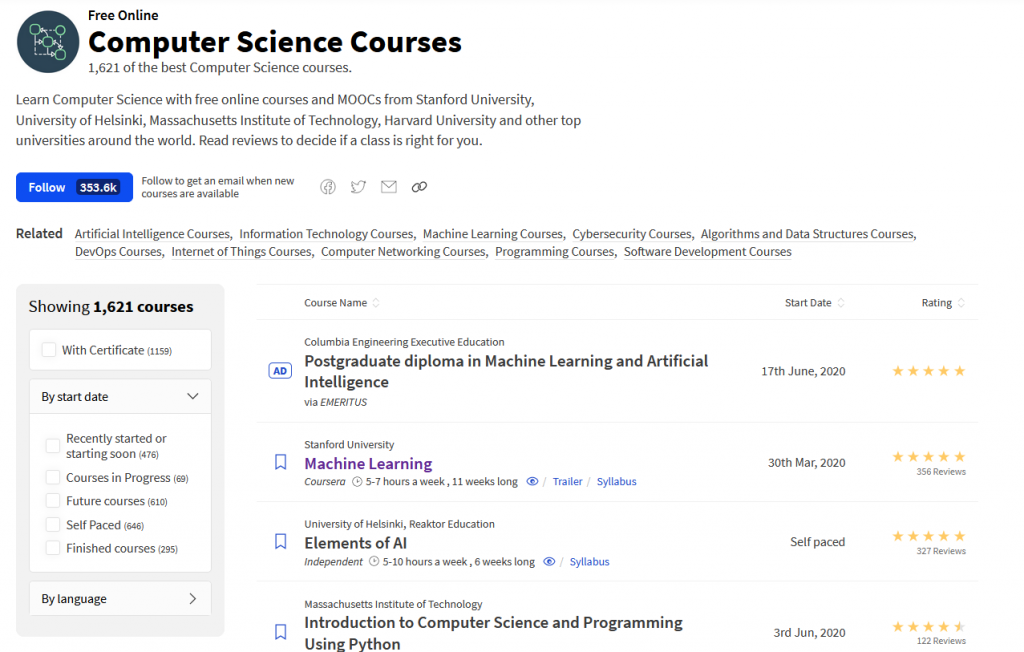
After selecting a category you’re taken to a search page where you can explore all courses tagged with this category. All searching and filtering is done client side.
Screenshot from Class Central – Select Course page
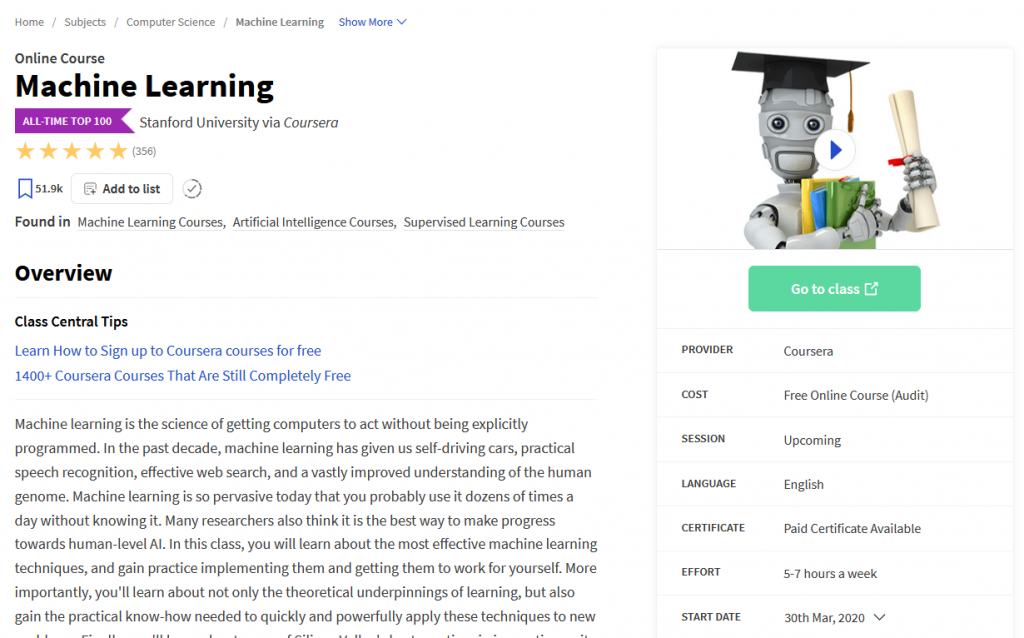
When selecting a course, you’re taken to a course overview page that consists of the course description, estimated duration, a button to start that course, etc..
Screenshot from Class Central – Course Overview page
Most of this front-end design can be based off existing MOOC sites. It’s the back-end of this application that is really interesting.
Back-end Implementation
First, there is one or more course list feeds. Each course in the feed has the type studytime_course. Each course item includes a name, description, keywords, and feed ID. One course list feed ID is hard-coded into the application and is downloaded or updated upon opening the application. Because the course list feed is the primary data source and only one person can add items to the feed, having a hard coded feed creates centralization. The application should not be centralized in any way, so to fix this users will be able to change the course list feed to one created by someone else. Users can load multiple course list feeds (perhaps MOOC providers could release their own StudyTime feeds), and the application will load the courses listed in each. If a course exists in multiple feeds it will be de-duplicated by feed_id and the metadata for the first version found will be displayed in the app.
Here’s what an item in a course list feed looks like:
While the user is browsing, StudyTime downloads the course feeds in the background, so there is little delay when opening a course. The courses will be grouped into categories client-side. Users can search, sort, and filter client-side using the name, description and keywords.
Each course has its own feed, where the author_id is the feed_id in the master feed. Each course feed contains the course content; the lessons and tests it contains, as well as hashes of all the images and videos in the course. When you view an image or video, StudyTime will request it from the SSB network then stream it from other peers who have a local copy. After an image or video is downloaded, the client will automatically share it with other peers to keep the network highly available. Here’s what a course feed looks like:
[{
author: '@Pyth0NEsential5.ed25519',
content: {
type: 'studytime_course_lesson',
lesson_number: 1,
name: 'Week 1 - How to install python',
description: 'This lesson will teach you how to setup Python on your PC',
lesson_content: 'In this lesson we will learn about installing python...'
}
},
{
author: '@Pyth0NEsential5.ed25519',
content: {
type: 'studytime_course_lesson_video,
lesson_number: 1
name: 'Week 1 Video 1',
description: 'How to install Python',
sources: [
'%c7ZAvQXoRP/zXnXgTnkGatP1JSAV29V8G/+Hhk8lSWU=.sha256',
'https://siasky.net/AABAC_3Dt0FJsxqsu_J4TodEETCGvtFf1Uys_3EgzO0Tcg',
'magnet:?xt=urn:btih:a3dced3979cc1a30cc7f648673ced688ce78ce77&dn=studytime-python-essentials'
]
}
},
{
author: '@Pyth0NEsential5.ed25519',
content: {
type: 'studytime_course_lesson',
lesson_number: 2,
name: 'Week 2 - Hello World',
description: 'This lesson will teach you the basics of python programming',
lesson_content: 'First lets run ipython with the following command:\n`ipython`...'
}
}]
The front-end uses these feeds to render the course contents and lesson pages, downloading required non-text content as users progress. It pre-fetches all course content in the background after starting a course, so users don’t have to pause at the beginning of each lesson. While browsing through courses, users can navigate quickly as the application is only rendering local data from the feeds.
Updating and Improving Courses
Over time courses may become out-of-date and need to be improved, edited or deprecated. SSB feeds are immutable append-only feeds, so the only way to make changes is via adding messages. A message type studytime_course_update is used to make these updates. Here’s an example of how the Python Essentials course above can be updated:
This update renames the course to Python 2.7 Essentials, and sets a deprecated flag. StudyTime hides all deprecated courses by default, but could have a “Show Deprecated” option for users that want to see them.
Similarly, course lessons can be updated with a studytime_course_lesson_update message, which contains a new name, description or lesson_content. The lessons will use the latest content when rendering.
Why build this on Scuttlebutt?
Scuttlebutt has a few advantages over building a traditional application with servers:
The creator doesn’t need to raise money or take down “unprofitable” content to keep the application running, because the community runs it with their collective computing and networking power.
Provided there are enough users, the application should never go offline, as users are constantly sharing feed data with each other. Because the content is being mirrored so many times, you will always be able to find a feed. Exceptions include images and video, which are harder to keep constantly mirrored, as they are only downloaded by the people that take a course. As a remedy, these images and videos could be mirrored to a service such as Sia or even S3 as a fallback.
Content cannot be censored or deleted by authorities.
These rules apply to any decentralized application built on Scuttlebutt. I am particularly excited about the first, because there are so many free websites I’ve loved that have closed down over the years simply due to lack of money. If the community supported them with bandwidth and computing power instead, they would last as long as they still have fans.
What are the drawbacks of using Scuttlebutt?
The downsides to using Scuttlebutt rather than centralized servers are mostly constrained to the initial release of the application:
If there are very few users online it may take a while to find and stream lesson content.
The developers of StudyTime may need to mirror most of the content until at least a few people have taken every course and are actively seeding the content.
SSB feeds cannot be changed, so there is no way to remove content once it’s been added. While it can be marked as deprecated/deleted so the application can hide it client-side, users will always have the information.
I hope someone either takes this idea and runs with it or becomes inspired by the potential this network brings. There are so many similar problems in many industries that could be saved with a decentralized back-end like Scuttlebutt.
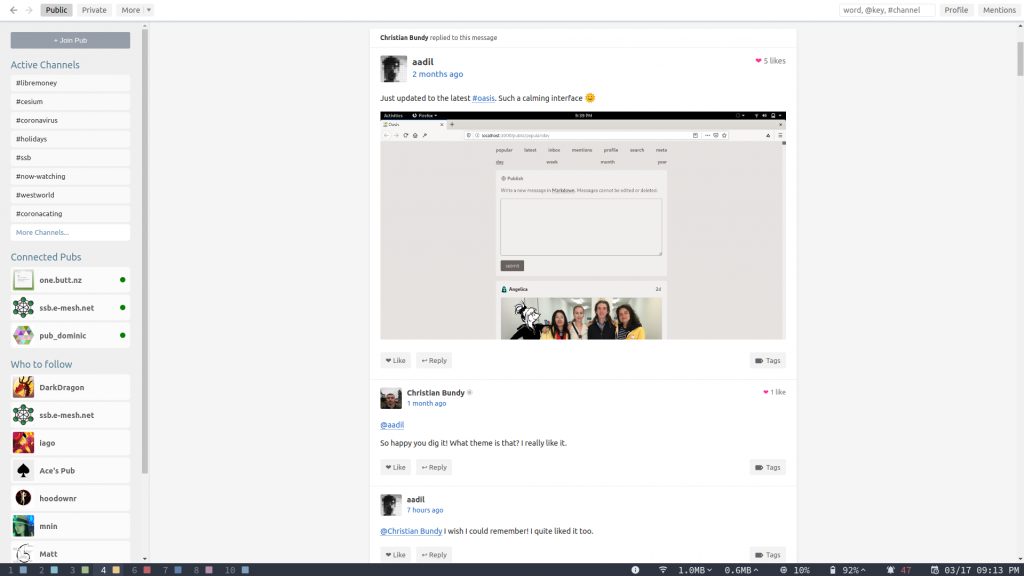
In what is scuttlebutt I discussed why Scuttlebutt can be a better social network than anything else out there. However, it can be so much more. It can be a decentralized platform that any application can be built on top of and immediately become peer-to-peer.
Under the hood, Scuttlebutt messages are just JSON data. Here’s what a normal text post looks like (simplified, additional metadata omitted for clarity):
Notice how the content sections of the post and vote are different? The only thing that is similar is the “type”, meaning the content section can be filled with anything you like. Different applications can send their own messages with their own ‘type’ and information, and clients that understand that type can display the information in a way that makes sense.
For example, you could build a chess application which sends content like:
This data is then sent along the Scuttlebutt network where any of your friends who have a chess client that can read the type “chess_move” can see that you’ve made the move “Qe4” which in Portable Game Notation means you moved a queen to e4. You could even play games of chess with people with other chess applications, as long as they can process this “chess_move” type. In fact someone has already built a ssb-chess backend that runs on Scuttlebutt and you can play it today.
Because everything is open source and you don’t need permission to join the network, you’re free to innovate as your heart desires. You can build any kind of application using Scuttlebutt as a network layer, and it’ll be decentralized and usable by anyone else on the network right out of the box.
For instance, someone could build an Instagram-like application that connects to Scuttlebutt, and shows all content of type ‘image’. Someone else could build a Twitter-like application that only displays text posts of less than 280 characters. These applications will talk on the same network as Patchwork, Manyverse, Patchfox, etc., and you can interact with friends using different applications seamlessly.
This means that you are free to choose the social application you use while still being able to connect to your friends on the same network. What if the developers of Patchwork do something you hate, like add sponsored content, rearrange the feed order, or make it neon orange and green for a real 90’s flair? Instead of being forced to “deal with it” like you are with Facebook or Twitter, you can simply download an alternative application like Manyverse or Patchfox and continue talking to all your friends with the same content. If you’re a programmer, you can even fork Patchwork, or create your own client from scratch just the way you like it. The application you use to view the world may constantly change, but the underlying data always remains the same.
This would allow Scuttlebutt to live on for decades or even centuries. Social clients may evolve and change over time just as they do now. People will build applications which will grow and die on it. But the underlying data remains the same, and you’ll never need to take your entire social world with you when switching clients again.
That’s what I love about the potential of Scuttlebutt. It’s not just freedom from corporate control, it’s freedom from anyone telling you what to do and how to interact with your friends. It’s freedom form the invisible hand nudging you to do things others want you to do, like clicking on ads or using their new live streaming product.
Remember AOL versus the Internet back in the 90’s? Initially everyone loved AOL as it was this beautiful walled garden that gave them news and information and games. But then the internet came along with infinite possibilities; a decentralized world where anyone can create and share and build what they like! It provided so much more utility and freedom that everyone flocked to it. That’s how I see Scuttlebutt today, the free alternative to the social media companies that only seem to be tightening their grip on their user-base, building a bigger wall around their garden every day.
As mentioned in Why Decentralization, a big focus of this site is the technologies that will make a decentralized world possible. Scuttlebutt is one I’m most excited about because it has a usable social network, and more applications can be built on it for free, without permission, by anyone.
Scuttlebutt solves multiple problems plaguing the social networking world:
One company having control over and access to everything people do and say on the network
AI algorithms sorting your timeline to decide what you should read, taking control away from you
Ads and the ability for companies to purchase attention, shoving themselves into your personal social timeline
That people have to have one profile tied to their real self
Technically Scuttlebutt isn’t a social network, it’s a system for building any kind of decentralized application, but explaining it in the context of a social network helps. Later I’ll be explaining how it has the potential to be so much more than this.
Scuttlebutt – the social network
Decentralized, open-source social networks have been tried before, the two most well known are Diaspora and Mastadon. With these services there are still servers that people gather around, so if you want an account you have to find a server and register for it. There is still moderation, there is still federation (you have to register an account, and you can get banned) and there are a few central points of failure (the servers themselves). While these networks are a great first step away from centralized corporate-controlled networks (I like them and will be exploring them in more depth soon), Scuttlebutt is how I believe the social web should function in the future.
Scuttlebutt’s fundamental difference is it is fully decentralized. Scuttlebutt is completely peer to peer, meaning there are no central servers that you connect to, and no one manages or controls the network. You don’t use a website to view Scuttlebutt, instead you download a client to your computer. When you use a client, like Patchwork, it talks directly to your friends over the internet. When you make a post it gets sent to all your friends, so they have a local copy of it. If a friend comes online while you’re offline, their client will automatically download your post/s from your mutual friends. Messages can spread between people constantly without everyone always needing to be online, just like the real world.
Patchwork – A Scuttlebutt client
When you download Patchwork and run it on your PC it’s initially empty, because you don’t know anyone and don’t know how to connect to anyone. You’ll notice you only need to enter a name, picture and description, there is no signup form. Why? Because Scuttlebutt has no central service to register with. You can be anyone you like, and no one can tell you otherwise. Instead of having a registration service Scuttlebutt creates a private key on your computer. This key is used to prove you are who you say you are to your friends, so that no one can impersonate you, and it’s controlled by you alone.
To begin you should connect to a “pub” with an invite code. A “pub” is a super-friend on the Scuttlebutt network who makes friends with everyone. Pubs are just like normal users except that they’re almost always online, identify as pubs, and will friend you automatically when you redeem an invite code. After you redeem an invite you become friends and can start downloading information about its other friends, their friends, and those people’s friends (3 degrees of separation). These pub servers are mostly run by Scuttlebutt developers. Connecting to a pub doesn’t restrict your network in any way, as they are just super-friends, not central servers.
While connecting to a pub isn’t required, until you have a few friends it’s worthwhile friending one. For one, pubs are almost always online, so whenever you come online you get all the latest gossip, instead of having to wait for friends to login. Second, pubs can help you discover more people, as you can communicate with anyone up to 6 degrees of separation away (3 degrees in each direction), and pubs are connected to other pubs, so they connect you to the whole Scuttlebutt universe.
Once you’ve downloaded the local gossip from the pub, you’ll see you now have a social feed in Patchwork. This feed is comprised of everything your friends are up to (of which you have 1 right now, the pub) and everything their friends are up to (2 degrees out). Though your client has information about people 3 degrees out for network redundancy purposes, you don’t see them in your feed by default. You can see them under the “extended network” menu option in Patchwork. So now you are connected to all these random people, what do you do? First I’d recommend checking out some of the hashtags/topics which you can see on the left, and subscribe to some that you find interesting. Once you’re subscribed to some topics you’ll see every post from everyone you know about that includes that hashtag.
You can then follow others who have similar interests to you and post anything you like to the network. Have fun out there! If you want to follow me my ID is: @Py8stqMfjhdc4Ln92R4Lg+3jITszP94G3P5BNuH+lWY=.ed25519
For the longest time humanity was decentralized. We had small communities of people who knew each other, maybe they had a king far away, but they didn’t really have anyone telling them how to live their lives, they were free to do what they want.
Along came the era of industrialization and some people discovered a thing called “economies of scale”. By building companies to control many people at once you could extract more value than anyone else.
Eventually social media happened and we were all so used to companies ruling our lives that we happily joined a world with all our friends, blissfully unaware of how much power the owner of this world was accruing.
Along comes the 2010’s and people start to realize they’ve been had. The fun happy social place they signed up to is actually ruled by a dictator and he’s started selling their data, changing the product to grow profits instead of individual happiness, and attempting to addict them every step of the way.
Eventually it comes to a breaking point and people are fed up. They join a new social network, run by a new smaller company that promises to do better and be better. This company becomes more profit-centric and exploitative over time, and the cycle continues. Alternatively they drop out of social media completely, keeping their lives almost as private as before the internet.
What if we could have the fun of a globally connected internet, without all the corporate control, exploitation, and addiction that goes along with it?
What if there was a social client that connected you directly to your friends, without any middlemen, so you can chat, share photos, play games and more, and that experience is yours alone? There are no ads, no addictive intrusions, no timeline sorted to be maximally good for the company.
Furthermore this social network is curated by you. You only see what you want to see, interact with those you care about, and can be anyone you want to be. Why do we have to link our social profile to our real identity anyway? Why can’t we be whoever we want to be in our social world?
What if you weren’t locked into just one social client, you could choose from hundreds? And they all worked on the same network seamlessly, so you and your friends could use different applications and still be together?
That’s the promise of a decentralized world, a beautiful magical place that you can tweak and change to your liking. A place that reflects your unique personality and outlook on life instead of being forced into a box with all the other humans.
This is the world I’d like to explore and build, together, over the next decade. Because we can’t leave the future of the internet (and the world) in the hands of so few.
This blog isn’t building a product and there’s nothing for sale here. It’s aim is to explore a decentralized world that could (and should!) exist, see the technologies that can make it happen today, and solve the problems that crop up along the way.
This world I describe has been partially built already! By a project called Scuttlebutt, and the Social Client that runs on it: Patchwork. You can start using them today. I’ll be explaining these in more depth along with other decentralization technologies over the coming months.